
多线程内存模型(2):内存屏障
重排序总的来说有四种类型
重排序类型
Load-Load 重排序
交换两个读取指令的顺序
1 | // 原始顺序 |
Store-Store重排序
交换两个存储指令的顺序
1 | // 原始顺序 |
Load-Store重排序
交换读取和存储指令的顺序
1 | // 原始顺序 |
Store-Load重排序
交换存储指令和读取指令的顺序
1 | // 原始顺序 |
屏障
CPU和编译器都预留了一些方法给我们阻止重排序,这些方法统称为屏障(Barrier)。根据之前提到的编译器重排和CPU重排,有编译器屏障和CPU屏障。
以这段代码为例,开启O2优化后b的赋值在a的赋值之前,这是编译器导致的重排序。
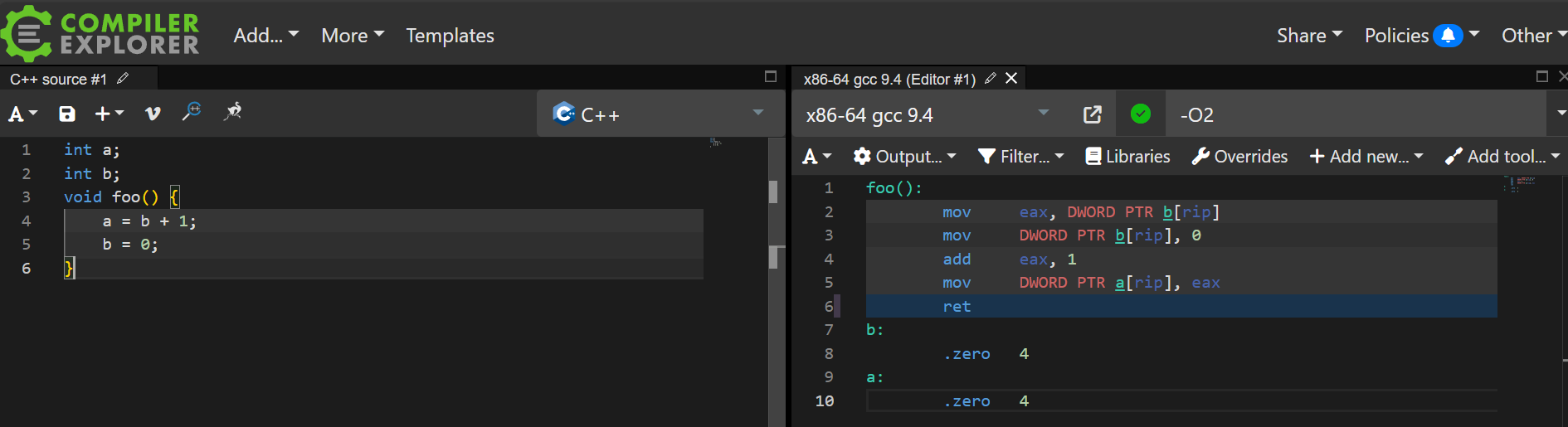
编译器屏障
编译器屏障用于阻止编译器重新排序特定的指令,GCC 提供了 asm 内联汇编语法来实现,即asm volatile("" ::: "memory")。
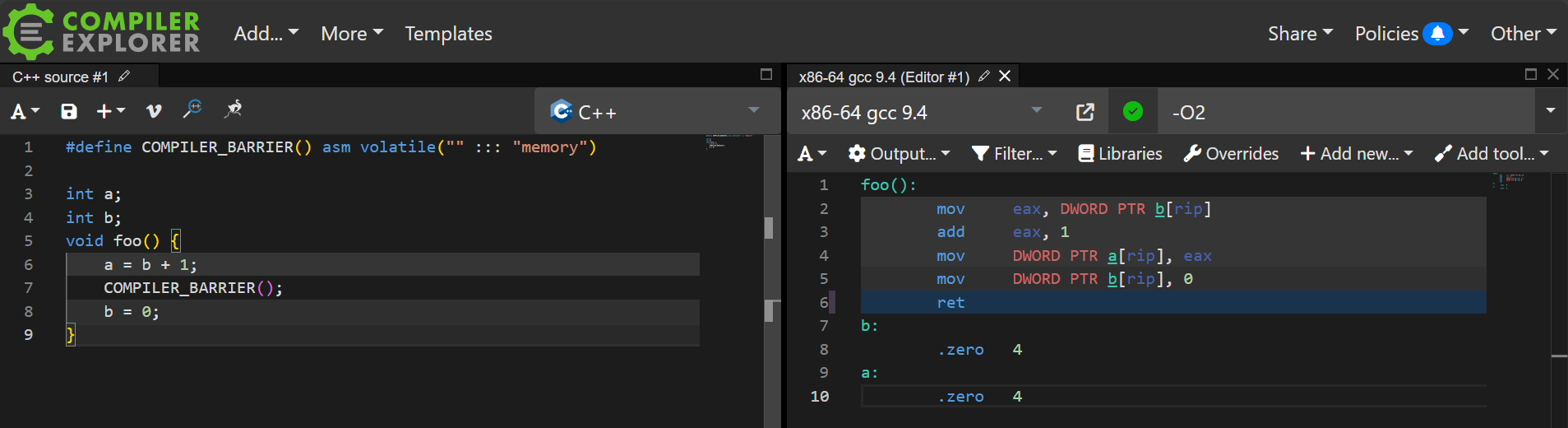
插入编译器屏障之后,编译器不会重新排序屏障之前和之后的指令。
内存屏障
即使编译器层面不会对代码进行重排,但在CPU层面还是可能会对代码进行重排,因此需要使用更底层的屏障。内存屏障,也叫运行时内存屏障(Runtime Memory Barrier)
编译器内置
GCC 提供了内置函数来实现这些屏障,__sync_synchronize 。这是一个全局内存屏障,确保在屏障之前的所有内存操作在屏障之后的内存操作之前完成。
当编译器识别到内存屏障时,默认不会对这部分的指令进行重排序。
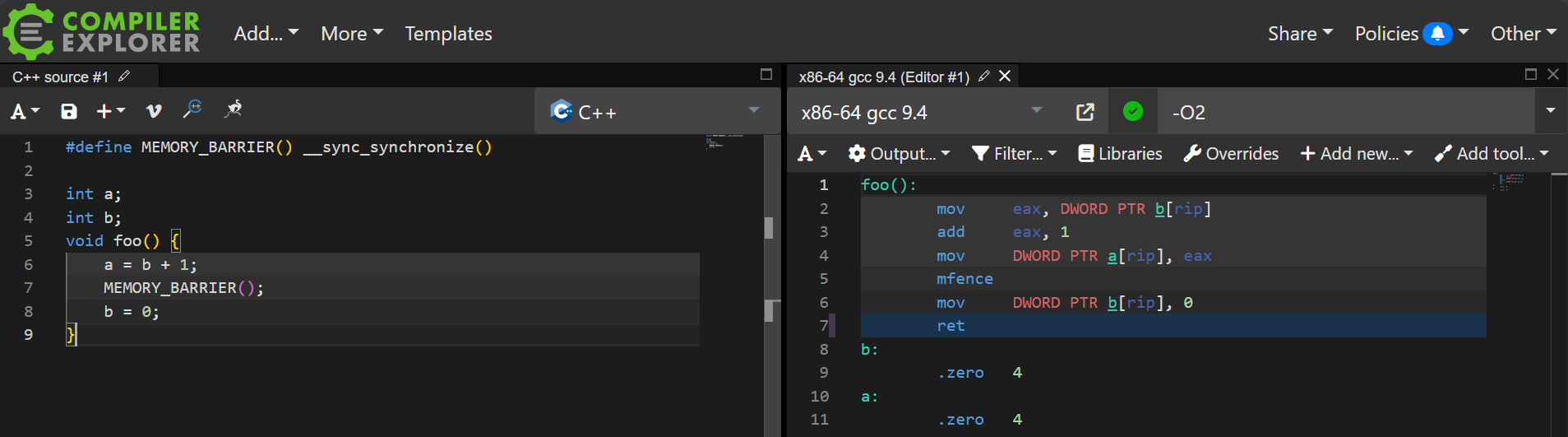
CPU指令
注意到调用__sync_synchronize函数后,汇编代码对应的位置会增加一条mfence指令,这是 x86 和 x86_64 架构中的一条内存屏障指令,用于强制对所有读写内存操作进行序列化。
内存屏障一共有三种:分为写屏障(Store Barrier)、读屏障(Load Barrier)和全屏障(Full Barrier),在 x86平台分别对应着sfence、lfence和mfence。
- mfence:全屏障确保在屏障之前的所有读和写操作在屏障之后的读和写操作之前完成
- lfence:读屏障确保在屏障之前的所有读操作在屏障之后的读操作之前完成
- sfence:写屏障确保在屏障之前的所有写操作在屏障之后的写操作之前完成
使用内联汇编来插入这些屏障指令的示例:
1 |
|
读屏障和写屏障的与第一部分提到的四种重排序有关,该部分与平台强相关,详细内容可以查阅官方手册
Intel® 64 and IA-32 Architectures Software Developer’s Manual
参考文章
多线程内存模型(2):内存屏障