
Transformer模型入门
Transformer模型最早是由Google在2017年发布的一篇论文《Attention Is All You Need》中提出。最早该方法用用于翻译任务中,发现性能能够超越之前最优秀的RNN模型。在后一年,Google发表的《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》提出了BERT模型,和OpenAI发布《Improving Language Understanding by Generative Pre-Training》提出了GPT模型,这两个著名的模型奠定了大模型的基础。
Transformer 最核心、最具革新性的特点是它完全依赖注意力机制来处理序列数据,彻底放弃了传统的循环神经网络(RNN,如 LSTM)和卷积神经网络(CNN)结构。它通过位置编码来实现对序列顺序的识别,在模型训练时没有前后依赖关系,可以实现高度并行化,显著提高训练效率,正是这一点使得大模型成为可能。
相比卷积神经网络只考虑附近数据的影响,Transformer有更大的感受野,更容易连接序列的任意位置,这也是Transformer的重要优点之一。
模型预览
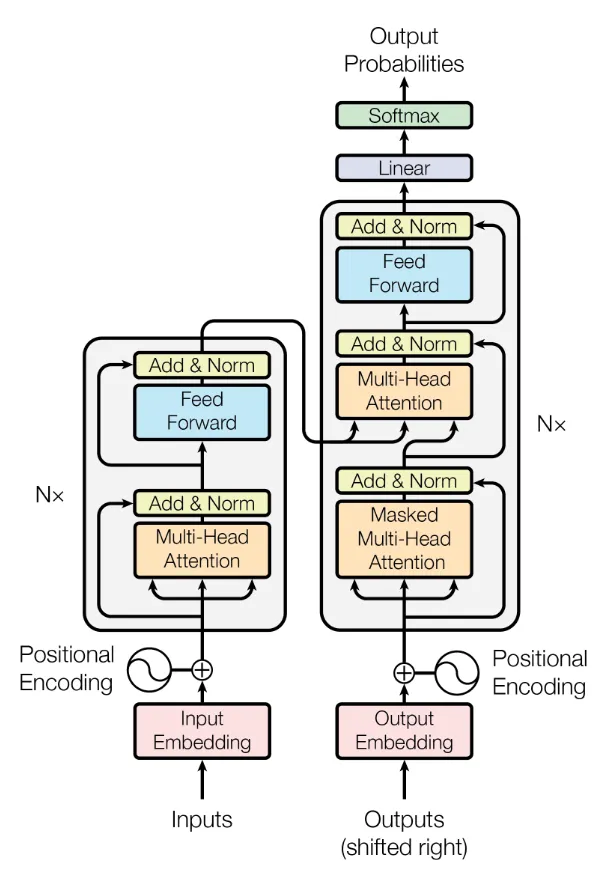
Transformer 模型遵循标准的**编码器-解码器(Encoder-Decoder)**架构,图例的左边是编码器,右边是解码器,模型由堆叠(stacked)的编码器和解码器组成。
编码器
编码器层每层包含2个组件,分别是多头注意力和全连接的前馈神经网络,每一层输出会使用层归一化和残差网络。
输入给编码器的序列需要加入位置编码信息,添加位置信息使模型感知序列的顺序。
解码器
解码器使用3个组件,分别是带有掩码的多头注意力层,多头注意力机制和全连接的前馈神经网络。
掩码用于掩盖后面位置的数据,保证数据不会被泄漏,这是自回归模型所需要的;第2个不带掩码的多头注意力机制层用于连接编码器和解码器。
相关阅读
10.7. Transformer — 动手学深度学习 2.0.0 documentation
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
How Transformers Work: A Detailed Exploration of Transformer Architecture | DataCamp
Attention? Attention! | Lil’Log
模型技术详解
Embedding
是一种将高维离散数据映射到低维稠密向量空间的技术。在机器学习中有一种one-hot编码方法,即用1表示状态或者属性存在,用0表示状态或者属性不存在。当状态非常多时,输入矩阵会变得非常的稀疏,embedding就是将高维的稀疏矩阵投影到低维中,减少输入矩阵的稀疏程度。
embedding的概念相对简单,实现起来要复杂的多,Embedding 的生成方式已经从Word2Vec等静态生成发展到基于Transform的动态生成,动态生成会根据上下文识别在当前语境中的语义。例如同样是苹果一词,在“苹果是一种好吃的水果”和“苹果是一个伟大的品牌”有着不同的含意,动态Embedding能够捕捉这些语境。随着进一步发展,现在有多模态Embedding,将文本、图像和音频等不同模态的信息映射到统一的向量空间中,使得跨模态检索成为可能(文本检索图像)。
相关阅读
embedding概念理解: 一文读懂Embedding的概念,以及它和深度学习的关系 - 知乎
embedding发展趋势综述:
from static to dynamic word representations a survey
从静态到动态,词表征近几十年发展回顾-腾讯云开发者社区-腾讯云
位置编码
与RNN和LSTM等序列模型不同,Transformer本身不具备处理顺序序列的能力。为了使Transformer能够感知到序列中的位置信息,需要为输入序列中的每个元素附加一个位置信息,形成一个新的输入向量。
位置编码有许多分类,论文中提出的正余弦位置编码属于绝对位置编码,后续也提出了相对位置编码和可学习位置编码,以及现在大模型广泛使用旋转位置编码。但总的来说,位置编码需要尽可能多的满足以下几个特性:
- 唯一性:每个位置的编码都是唯一的;
- 能够体现相对位置信息:任意一个词,知道其他的词哪些是离得比较近的;
- 外推性:当推理输入的长度超过训练的最大长度时,依然能够很好的处理;
- 有界性:位置编码的置应该有边界。
相关阅读
Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad’s Blog
Transformer学习笔记一:Positional Encoding(位置编码) - 知乎
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
多头注意力机制
注意力机制是Transformer模型的核心,理解起来有相当大的困难。一个学习建议就是先将公式和实现代码背熟,知道具体是怎么计算的,再回去看有关解释的文章。
推导公式
定义一个长度为N的输入序列:
接着在做 self-attention 之前,会用词嵌入向量计算 $q,k,v$ 向量同时加入位置信息,函数公式表达如下:
$$
\begin{gathered}
\boldsymbol{q}_m=f_q(\boldsymbol{x}_m,m) \
\boldsymbol{k}_n=f_k(\boldsymbol{x}_n,n) \
\boldsymbol{v}_n=f_v(\boldsymbol{x}_n,n)
\end{gathered}
$$
其中 $q_m$ 表示第 $m$ 个 token 对应的词向量 $x_m$ 集成位置信息$m$之后的 query 向量。而$k_n$和$v_n$则表示第n个token对应的词向量 $x_n$ 集成位置信息$n$之后的 key 和 value 向量。
而基于transformer的位置编码方法都是着重于构造一个合适的$f(q,k,v)$函数形式。
而计算第$m$个词嵌入向量 $x_m$ 对应的 self-attention 输出结果,就是$q_m$和其他$k_n$都计算一个 attention score ,然后再将 attention score 乘以对应的 $v_n$ 再求和得到输出向量$o_m$ :
Pytorch代码实现
1 | class MultiHeadAttention(nn.Module): |
相关阅读
Q、K、V 与 Multi-Head Attention 多头注意力机制 - 知乎
Transformer模型入门