
模型训练推理优化实践(一):训练优化
NVIDIA提供了一些适用于CUDA层面的Profiling工具,其中最重要的是Nsight产品族的性能分析工具Nsight Systems、Nsight Compute和Nsight Graphics。
这里两个工具使用上互补,Nsight Systems更侧重整个系统性能分析,监视了CPU、GPU、内存和网络等资源的情况,可以识别系统整体的瓶颈。除了CUDA之外,也支持OpenGL、DirectX、Vulkan、CPU 线程等分析。
Nsight Graphics更适用于内核级微观分析,优化算子的计算效率。
例如,使用Nsight Systems和Nsight Compute对AI应用实现性能分析与优化的流程为:
- 先利用Nsight Systems观察到某个CUDA Kernel具体运行时间的功能,分析一下程序。
- 如果发现某个Kernel运行时间过长,可以使用Nsight Compute对这个CUDA Kernel做进一步的性能分析并进行优化。
- CUDA Kernel如果优化完成,可以再次使用Nsight Systems对程序做Profiling,如此反复,直到整个程序的性能优化达到预期结果。
环境准备
该实践需要安装以下环境:
- pytorch(GPU版本):用于下载、加载和训练和推理模型
- nvtx:在程序中插入标记和区间,更清晰地可视化代码执行过程,便于性能分析与调优。
- torch-tensorrt: 推理优化库
训练优化实践
创建示例模型
当搭建完一个深度学习网络,您可以使用NVIDIA Nsight Systems工具进行基准性能分析,观察哪些地方可以做优化。本文以TensorBoard-plugin tutorial中的示例模型为例,演示如何利用NVIDIA Nsight Systems工具寻找模型优化的机会。操作步骤如下所示。
创建一个如下的main.py文件
1 | import nvtx # 引入nvtx包,便于在nsight system中观察各个函数的逻辑关系。 |
执行以下命令,会在当前目录下生成名为baseline.nsys-rep的文件。
1 | nsys profile \ |
预期输出:
1 | Files already downloaded and verified |
将baseline.nsys-rep文件导入Nsight System UI中,即可对模型进行分析。如下为初次打开的效果图: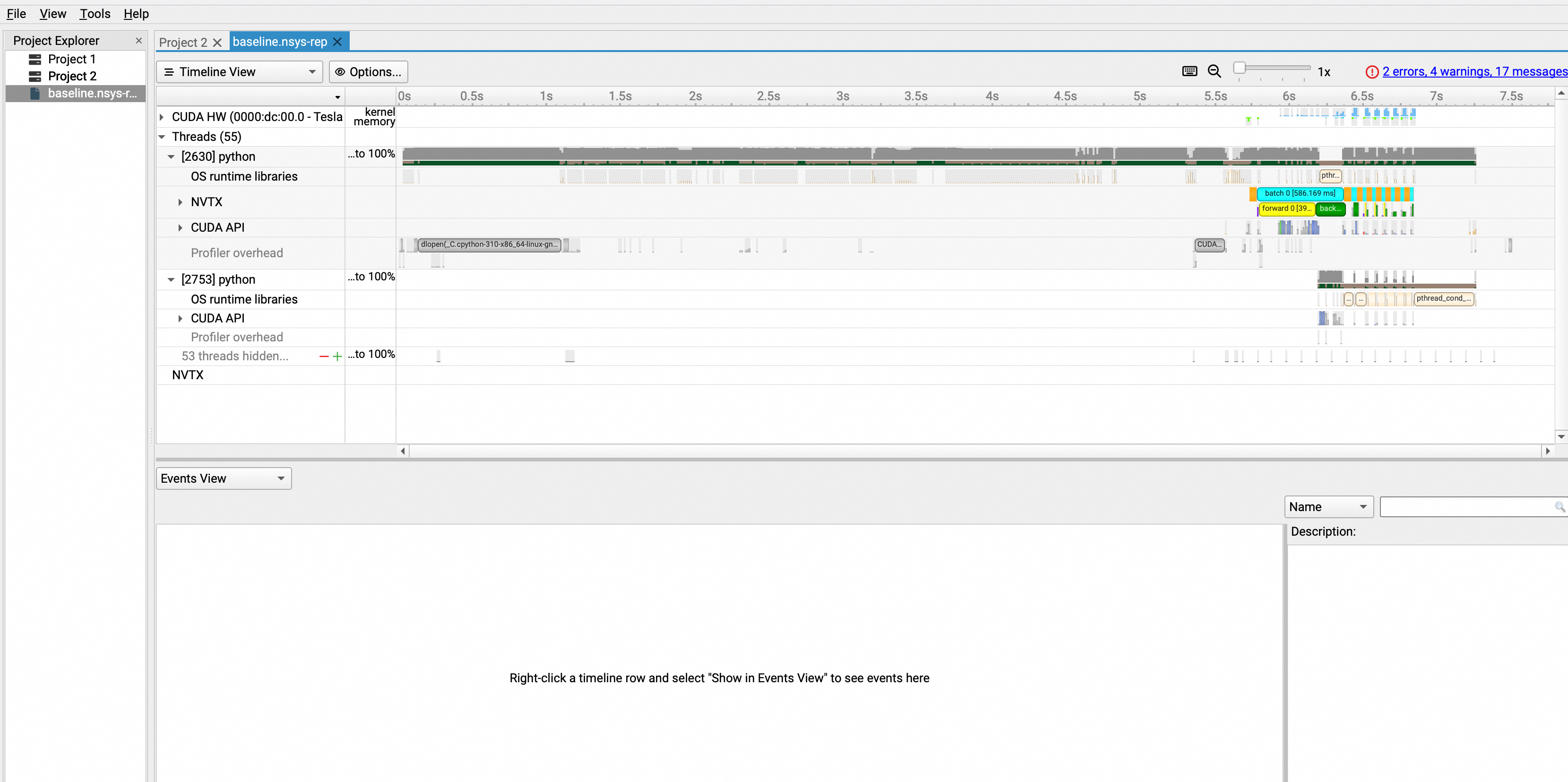
本文仅参考最后3个Batch(前3个Batch可能会受到初始化和预热效应的影响,性能评估不准确)。如下所示,放大最后3个Batch的位置。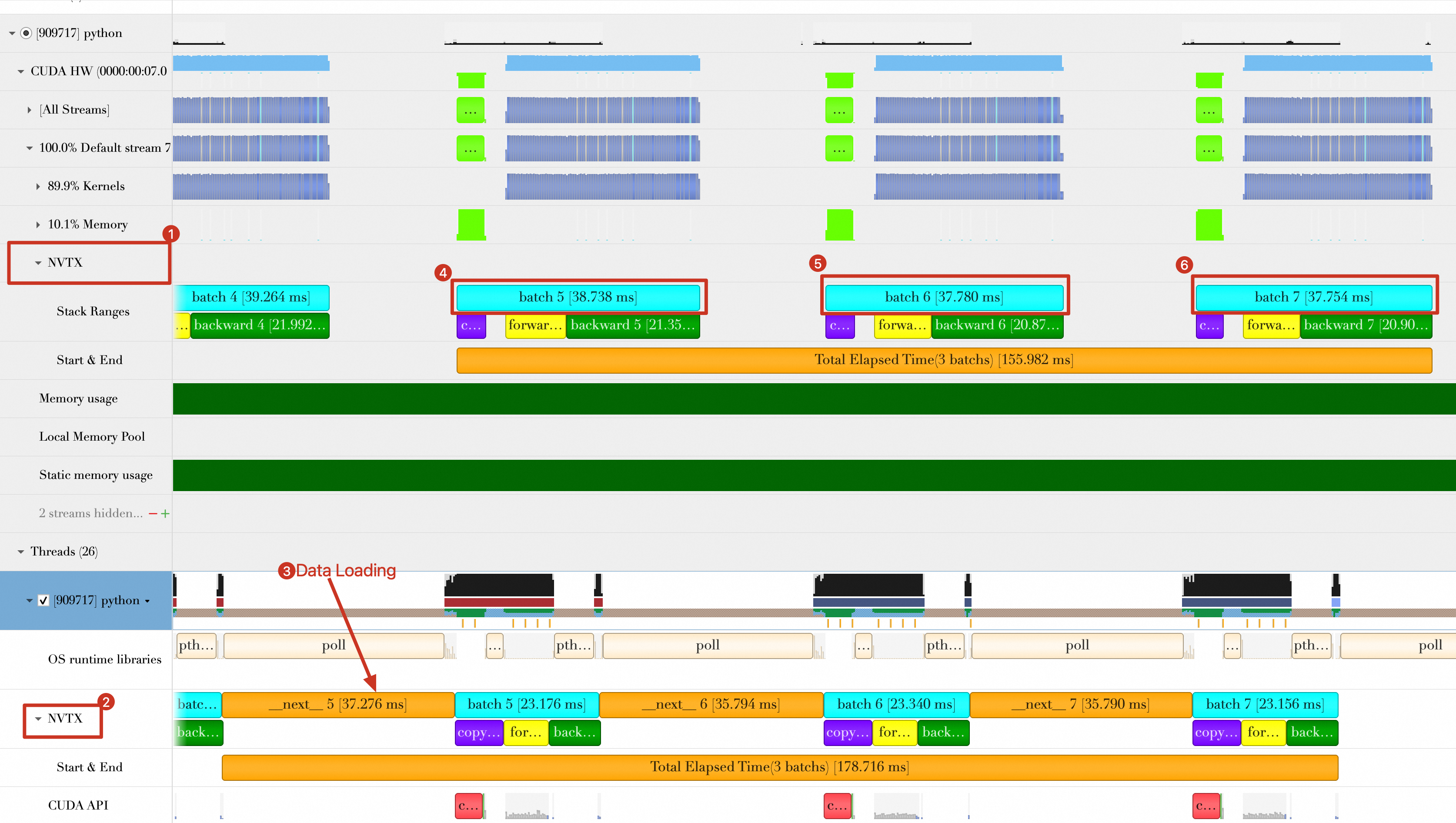
图中有2个NVTX记录Batch时间,一个是在CUDA Stream(Default Stream)中(图中标号为1),一个是在Python线程中(图中标号为2),两者统计的Batch时间(包括copy data、forward、backward)有很大差别。因此如果调用CUDA API并在GPU上运行核函数,此时以在CUDA Stream中的NVTX为准(也就是标号1的数据),这是因为Batch传输和GPU计算对于CPU来说是异步的,Python线程中统计的可能不太准确。
Batch数据加载和Batch计算(包括将Batch传输到GPU)是重叠的,从上图中可以看到,当进行Batch 6的加载操作时,GPU端仍然在计算Batch 5,所以在后续计算3个Batch的总持续时间时,重叠部分不计算时间。
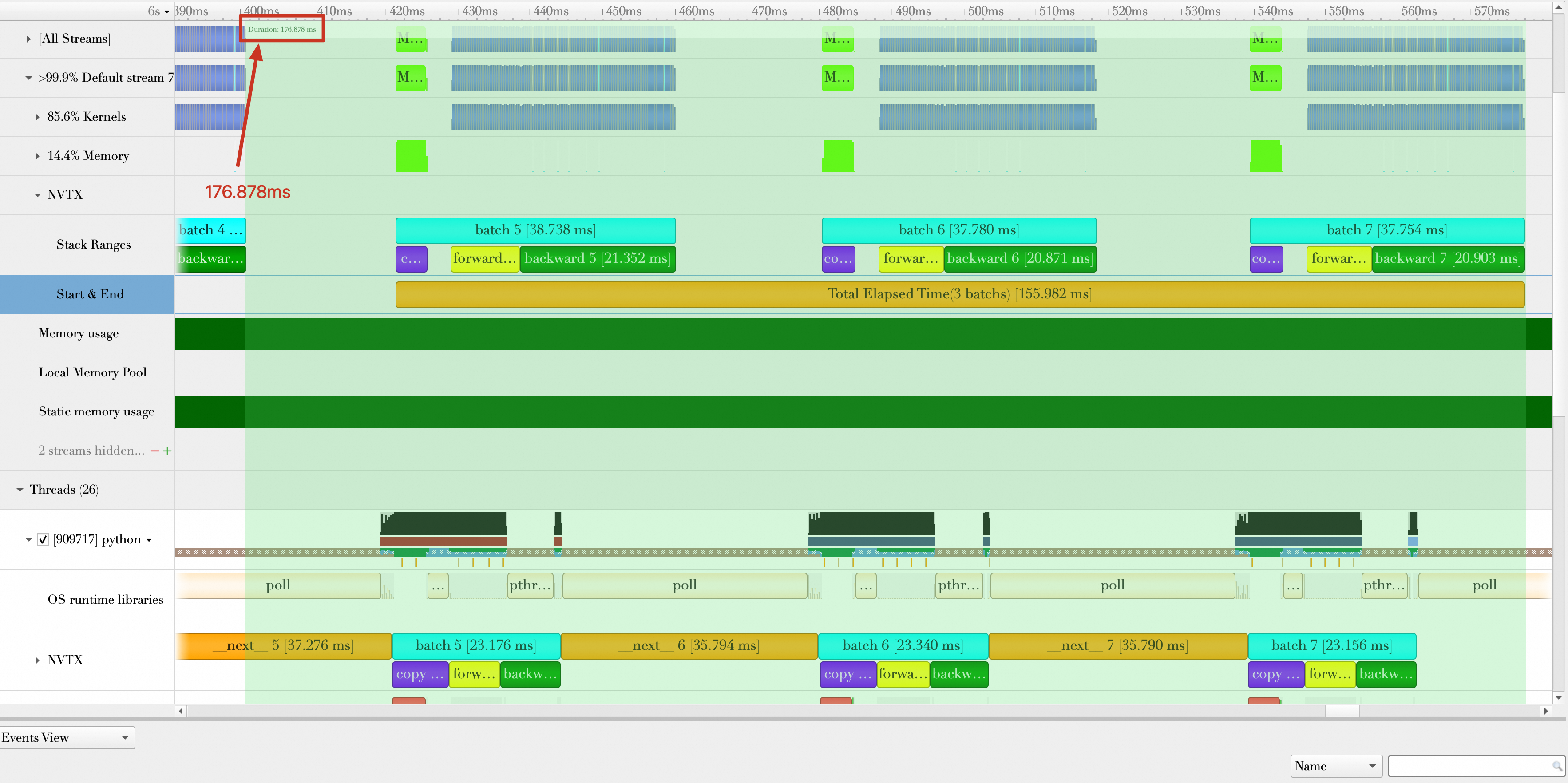
对Baseline各个阶段的持续时间统计如下:
| 各阶段持续时间 | 耗时(单位:ms) |
|---|---|
| 平均数据加载时间(图中标记:next) | (37.276 + 35.794 + 35.790) / 3 = 36.287 |
| 平均数据传输时间(图中折叠未显示出) | (4.39 + 4.363 + 4.317) / 3 = 4.357 |
| 平均Batch处理时间(包含数据传输、forward、backward) | (38.738 + 37.78 + 37.754) / 3 = 38.091 |
| 3个Batch总的持续时间(如下图所示,从第5个Batch数据加载到第7个Batch计算完成) | 176.878 ms |
| 平均每秒处理样本数(单位:samples/s) | 32(batch size) * 3 / (176.878 / 1000) = 542.746 |
步骤二:优化和分析模型
模型优化流程
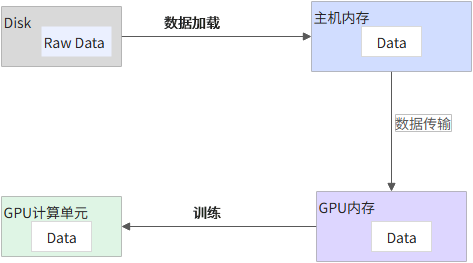
对于一个单机的深度学习训练任务,主要分为如下几个阶段:
数据加载(Data Loading):通常情况下,把数据从Disk(或者其他网络存储系统)加载到主机内存,并对数据做预处理操作(例如,去除噪声值),笼统地称为数据加载阶段。
数据传输(Data Transmission):将数据从主机内存传输到GPU内存。
训练(Training):GPU计算单元(CUDA Core、Tensor Core)利用这些数据做训练操作。
以下将对每部分做一些案例介绍。
优化方向1:缩短数据加载(Data Loading)时间
对于一个训练任务而言,缩短数据加载时间对整个训练任务有很大的帮助,如果数据加载时间大于GPU训练的时间,就有可能造成GPU空闲(等待数据加载)。
如下图所示,在Baseline(不包含任何优化措施)中,Batch与Batch计算之间存在很大的空隙,引起这些空隙的根因在于Batch数据加载时间比较长,GPU需要长时间等待数据加载完成才能处理这个Batch的数据,所以数据加载成为整个训练任务的瓶颈。
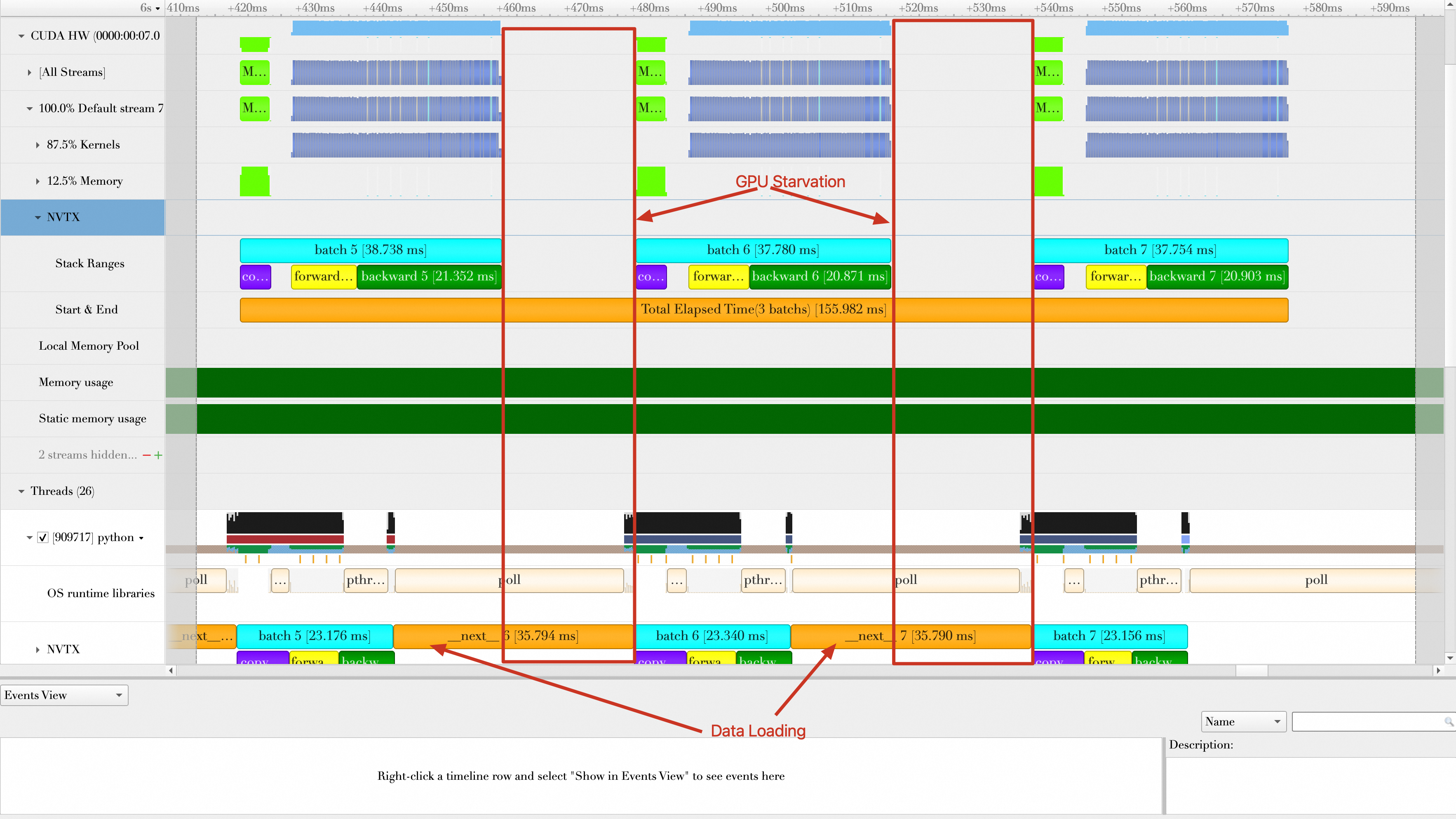
PyTorch的DataLoader支持多个Worker(Multi-process)同时工作,加载某一个Mini Batch的数据。修改main.py文件中的train_loader参数,尝试设置8个Worker加载数据。
1 | train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=32, shuffle=True) |
重新运行,可以看到Batch与Batch之间已经没有空隙,同时数据加载时间大大缩小,三个Batch加载平均消耗时间为:(2.879 ms + 104.995 us + 180.066 us) / 3 = 1.055 ms。同时,每秒处理样本数(samples/s)为:32 * 3 /(120.328 / 1000)= 797.819(注意数据加载时间已经隐藏在GPU计算中,所以忽略),性能相比Baseline提升(797.819 - 542.746)/ 542.746 * 100% = 47.00%。
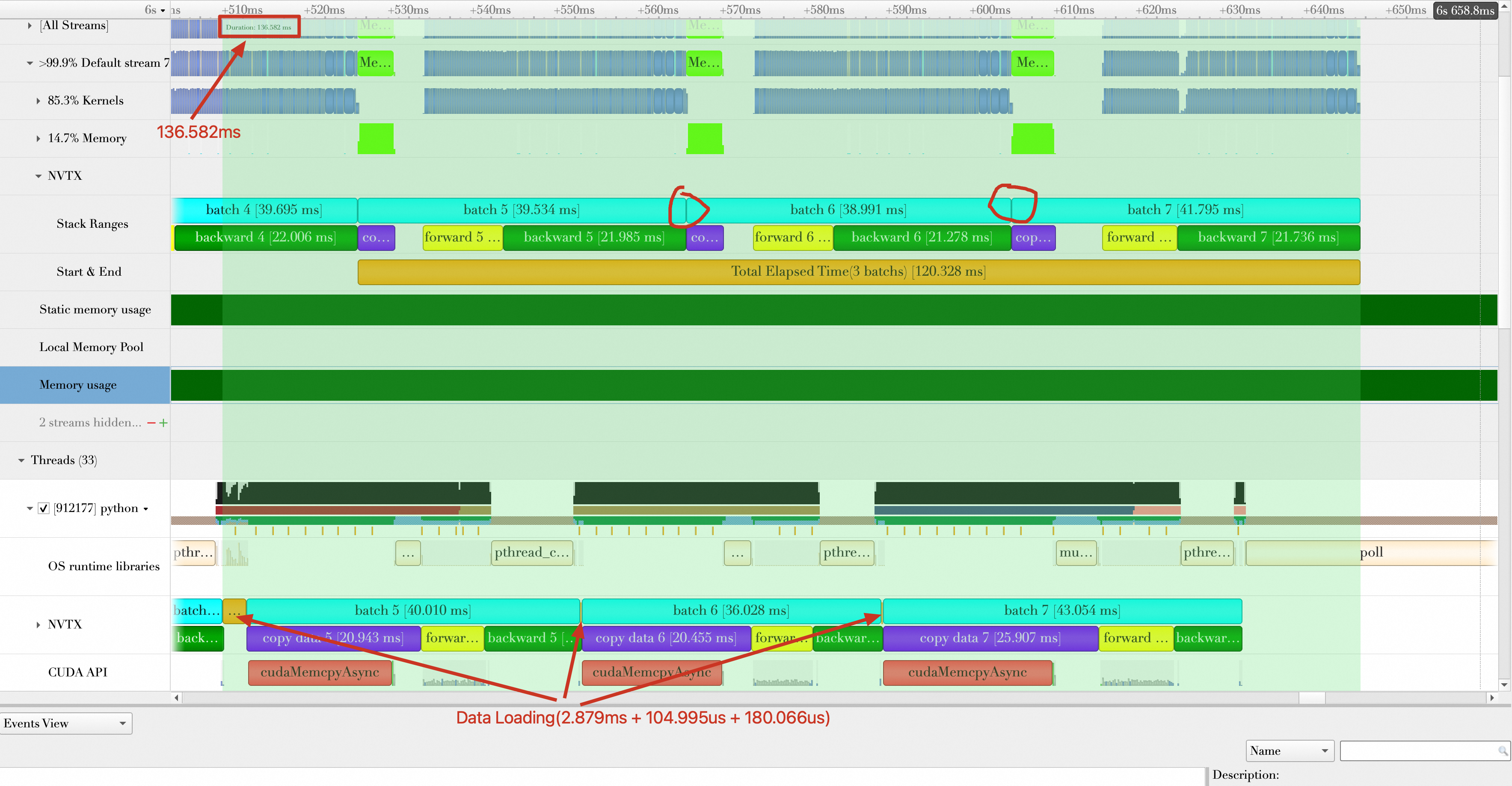
优化方向2:缩短数据传输(Data Transmission)时间
在设置8个Worker的基础上,可以继续寻找示例模型训练中可优化的点。在上述的分析中,可以看到数据传输平均时间为4.357 ms,尝试开启Pin Memory来缩短数据传输时间。
在PyTorch中,支持将加载的数据直接存放在Pin Memory中。如下所示,修改main.py文件中的train_loader参数,开启Pin Memory。
1 | train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=32,pin_memory=True, shuffle=True) |
重新运行代码,可以看到数据传输的平均时间为:(1.956 + 1.979 + 1.989)/ 3 = 1.975 ms,相比Baseline时间缩短4.357 ms - 1.975 ms = 2.382 ms。总的持续时间缩短为99.535 ms,平均每秒处理样本数(samples/s)为:
32 * 3 /(99.535 / 1000) = 964.485,性能提升(964.485 - 797.819)/ 797.819 * 100% = 20.89%
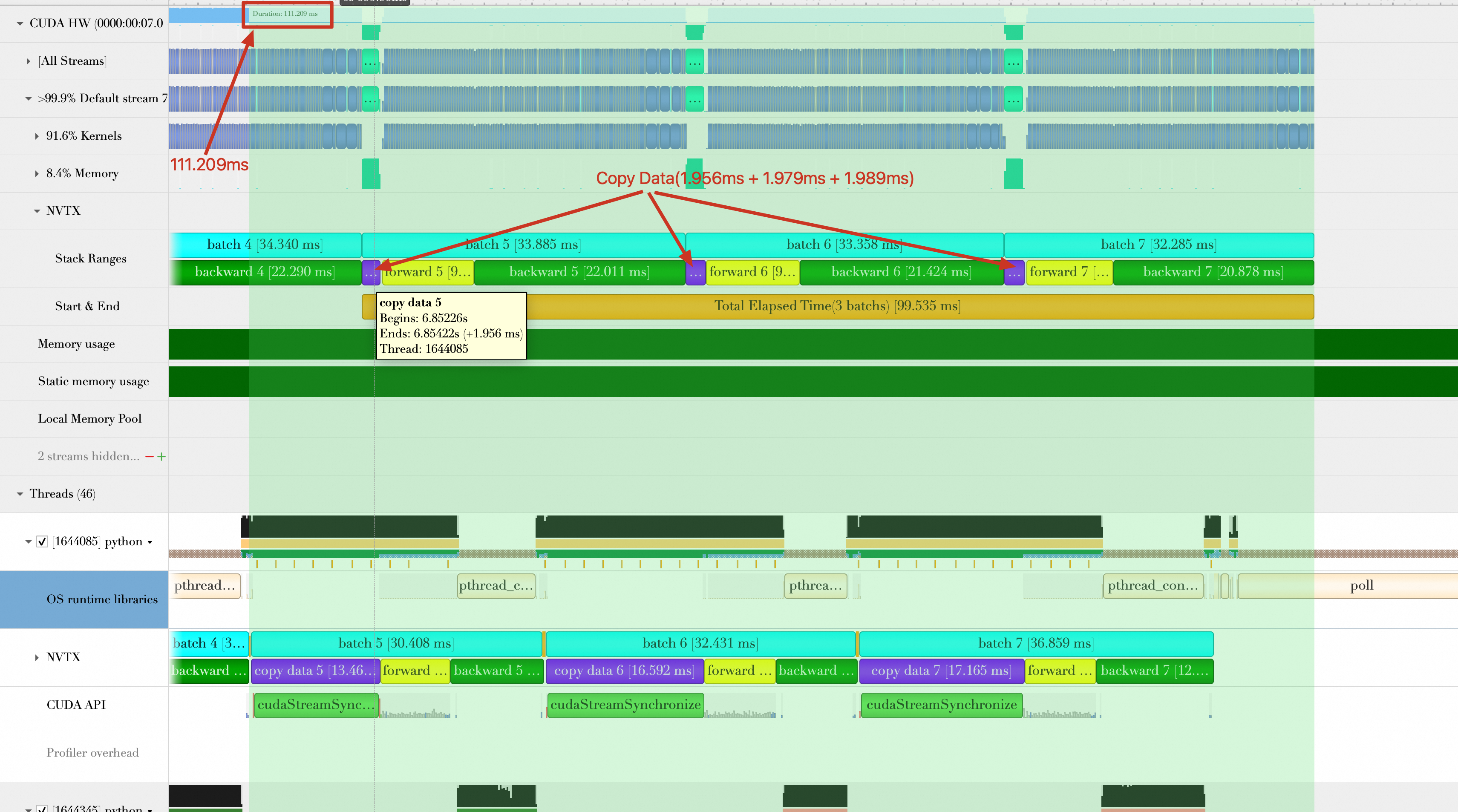
优化方向3:数据加载和数据计算完全重叠
在缩短数据传输时间的基础上,继续寻找优化的机会。分析开启Pin Memory的Timeline发现,虽然Batch加载和Batch计算(包括Batch传输)有重叠效果,但是Batch加载却只能重叠一个Batch计算,如下图,Batch5的加载与Batch4的计算重叠,Batch6的加载与Batch5的计算重叠,Batch7的加载与Batch6的计算重叠。并没有出现例如加载Batch6、Batch7与Batch5计算重叠的情况。同时,在Timeline中发现,在数据加载操作的后面,都会出现一次cudaStreamSynchronize,强制CPU与GPU做一次同步操作,然而每次计算Batch时并不需要这个同步操作。
这个同步操作是由如下的这行代码引入的:
1 | inputs, labels = data[0].to(device=device), data[1].to(device=device) |
to函数默认行为是:每次将数据从Host端传输到GPU端后,会执行cudaStreamSynchronize进行同步。然而,to函数亦支持非阻塞模式(异步操作),通过添加参数non_blocking=True来实现:
1 | inputs, labels = data[0].to(device=device,non_blocking=True), data[1].to(device=device,non_blocking=True) |
采用非阻塞模式后(异步操作),数据传输至GPU的操作被安排至CUDA流队列末尾而不会阻碍CPU,即CPU可继续执行后续任务,无需等待数据传输完成。
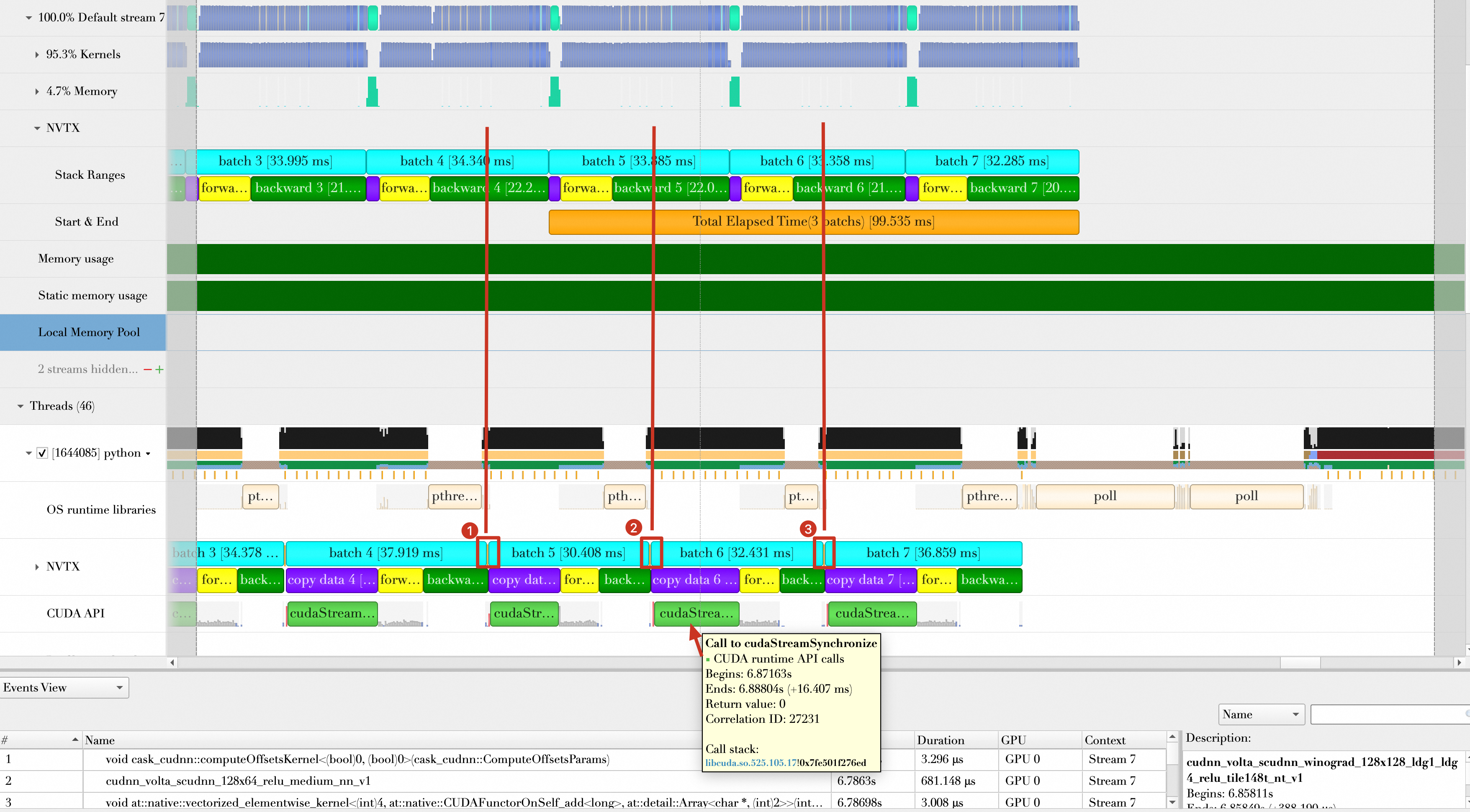
修改代码后,重新运行,结果显示如下。
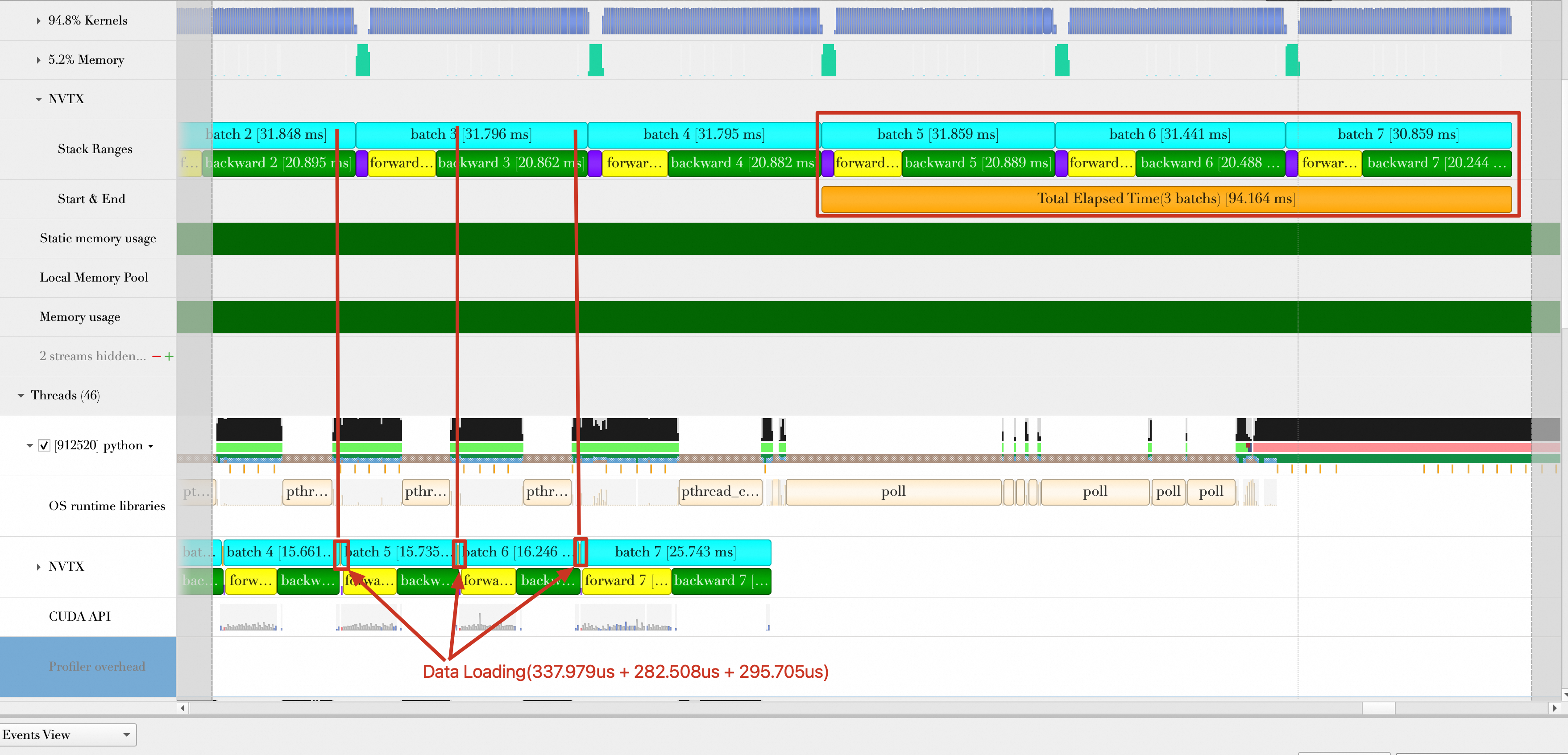
从上面的图中可以看出:
GPU真正在计算Batch3时,CPU端Batch5、Batch6、Batch7数据加载已经完成(也就是CPU早早完成自己的任务),真正做到Batch加载与Batch计算完全重叠。
Batch5、Batch6、Batch7的加载已经完全隐藏在了Batch2、Batch3、Batch4的计算中,它们的加载时间可以忽略不计。
每秒样本处理数(samples/s)为:32 * 3 / (94.164 / 1000) = 1019.498。相比上一步的优化2,性能提升(1019.498 - 964.485)/ 964.485 * 100% = 5.7%。
优化方向4:自动混合精度
前面已经优化了数据加载、数据传输。本次将聚焦寻找一些降低GPU计算Batch时间的方法。
PyTorch支持在训练的时候开启混合精度计算( Automatic Mixed Precision (AMP)),在AMP模式下,GPU上部分Tensor自动转换为低精度的16位浮点数,并在GPU张量核心上运行,以此降低显存使用量和缩短计算时间。
修改下面的代码开启AMP模式。在生产环境中,AMP的完整实现可能需要梯度缩放,下方代码演示中没有包括这一点,请参考相关文档正确使用AMP。
1 | # train step |
开启AMP的结果如下。Batch计算时间缩短为58.938 ms,平均每秒处理的样本数为:32 * 3 / (58.938 /1000) = 1628.83,性能提升(1628.83 - 1019.498)/ 1019.498 * 100% = 59.77%。
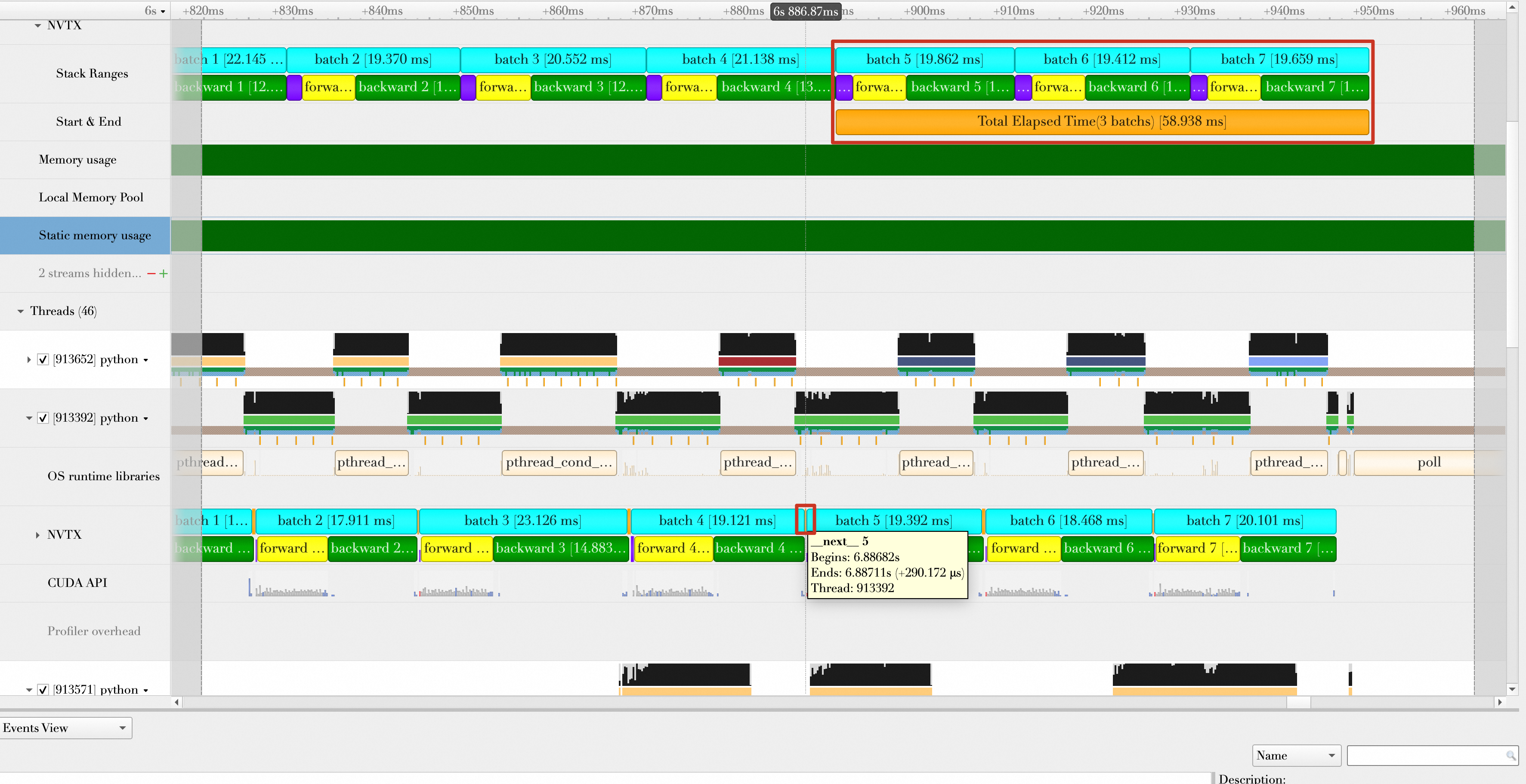
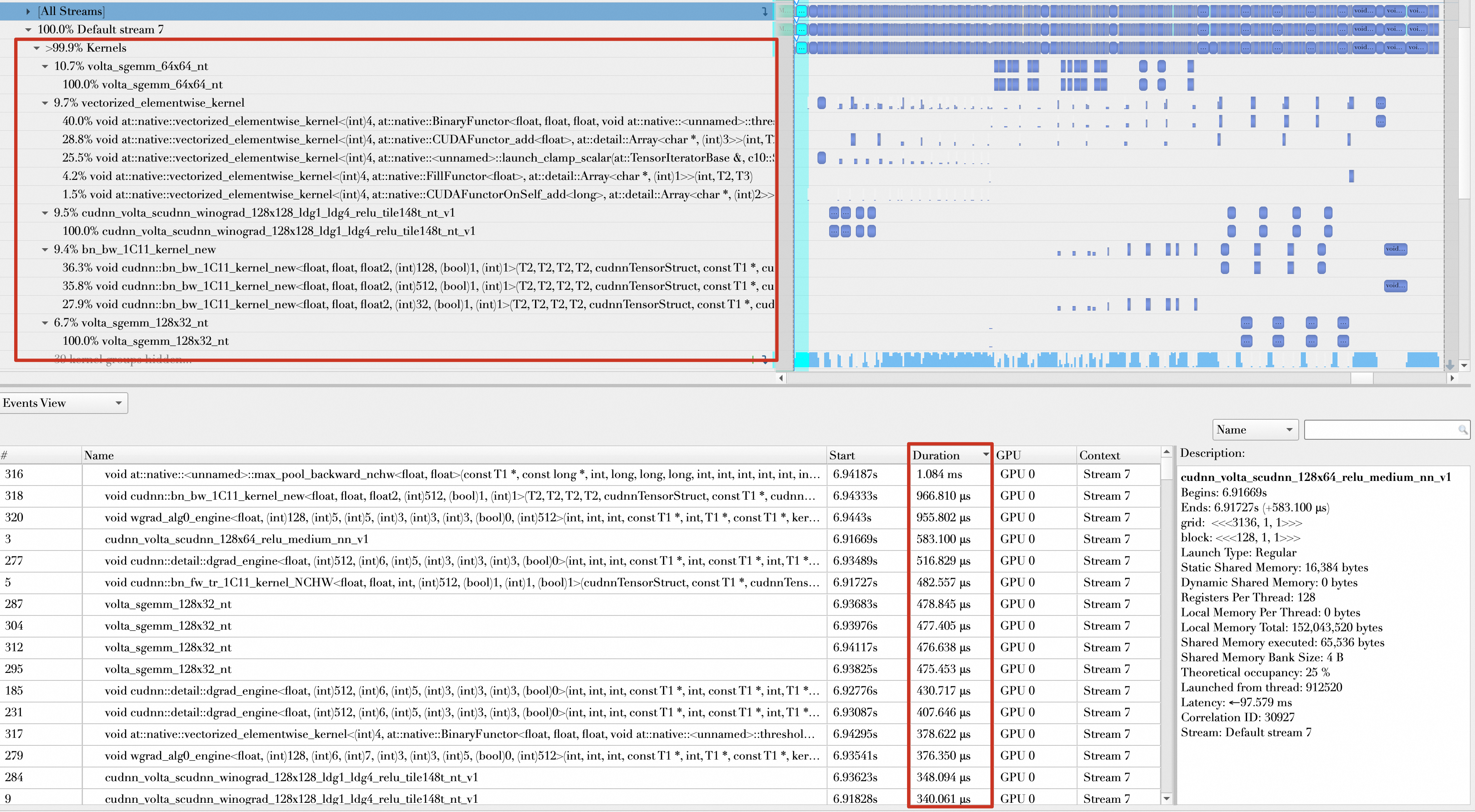
进入一个Batch的forward和Backward,观察其Kernel函数的组成,发现开启AMP之前,操作的数据类型基本都是float32,并且将Kernel函数执行时间按降序排列,执行时间靠前的如下所示,从300μs到1ms不等。
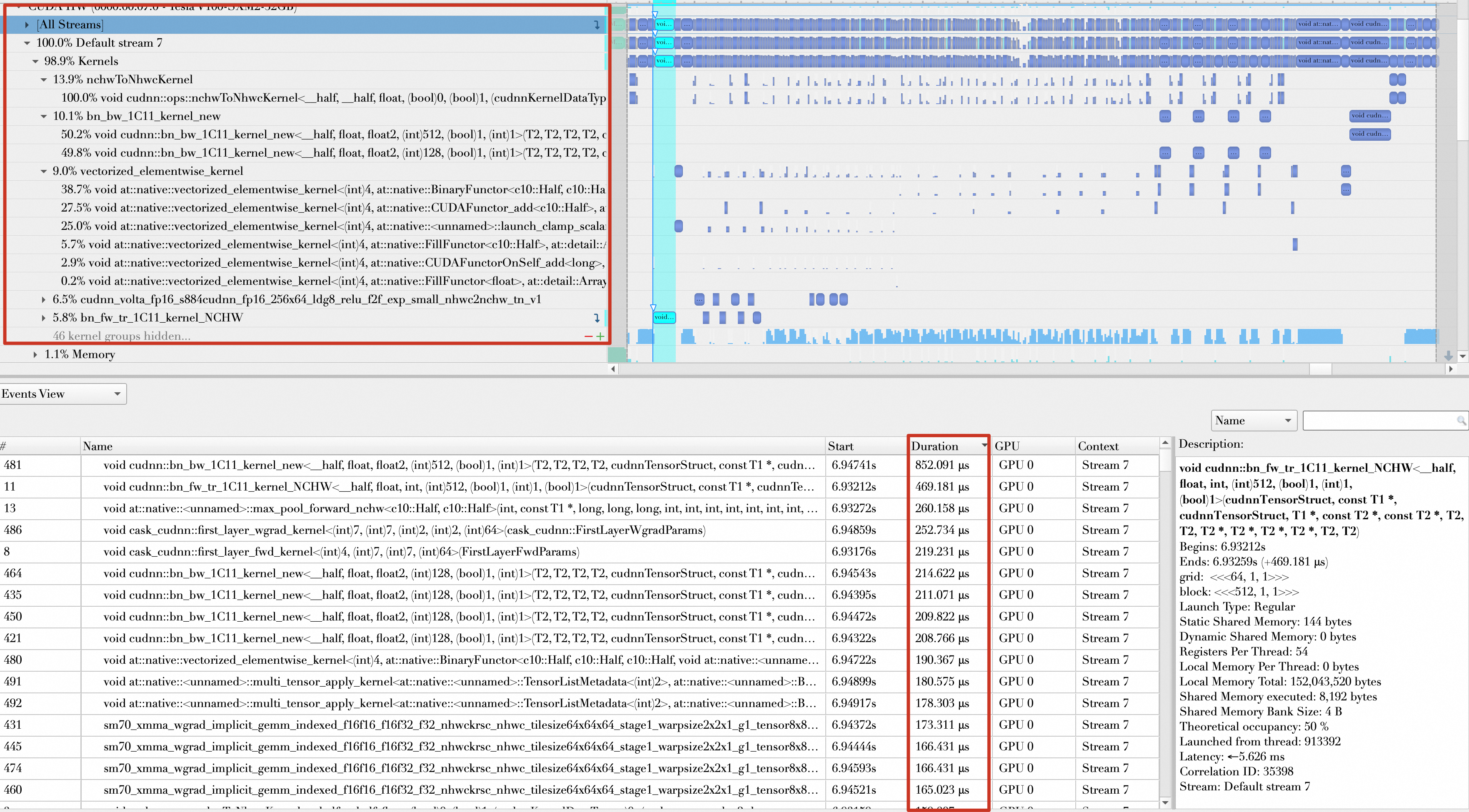
开启AMP以后,大多数操作的数据类型都是float16,并且执行时间靠前的Kernel基本都在100μs到300μs之间。
优化方向5:增大Batch Size
增大Batch Size也能够提升每秒处理样本数,但是增大Batch Size需要考虑显存的使用情况(显存是否够用)和大Batch Size对Loss值的影响。
修改如下代码,尝试将Batch Size从32调整至512。
1 | train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=512,pin_memory=True, shuffle=True) |
运行代码,结果如下。总的持续时间为:697.666 ms,平均每秒处理样本数(samples/s)为:512 * 3 /(697.666 / 1000)= 2201.627。性能提升(2201.627 - 1628.83)/ 1628.83 * 100% = 35.17%。
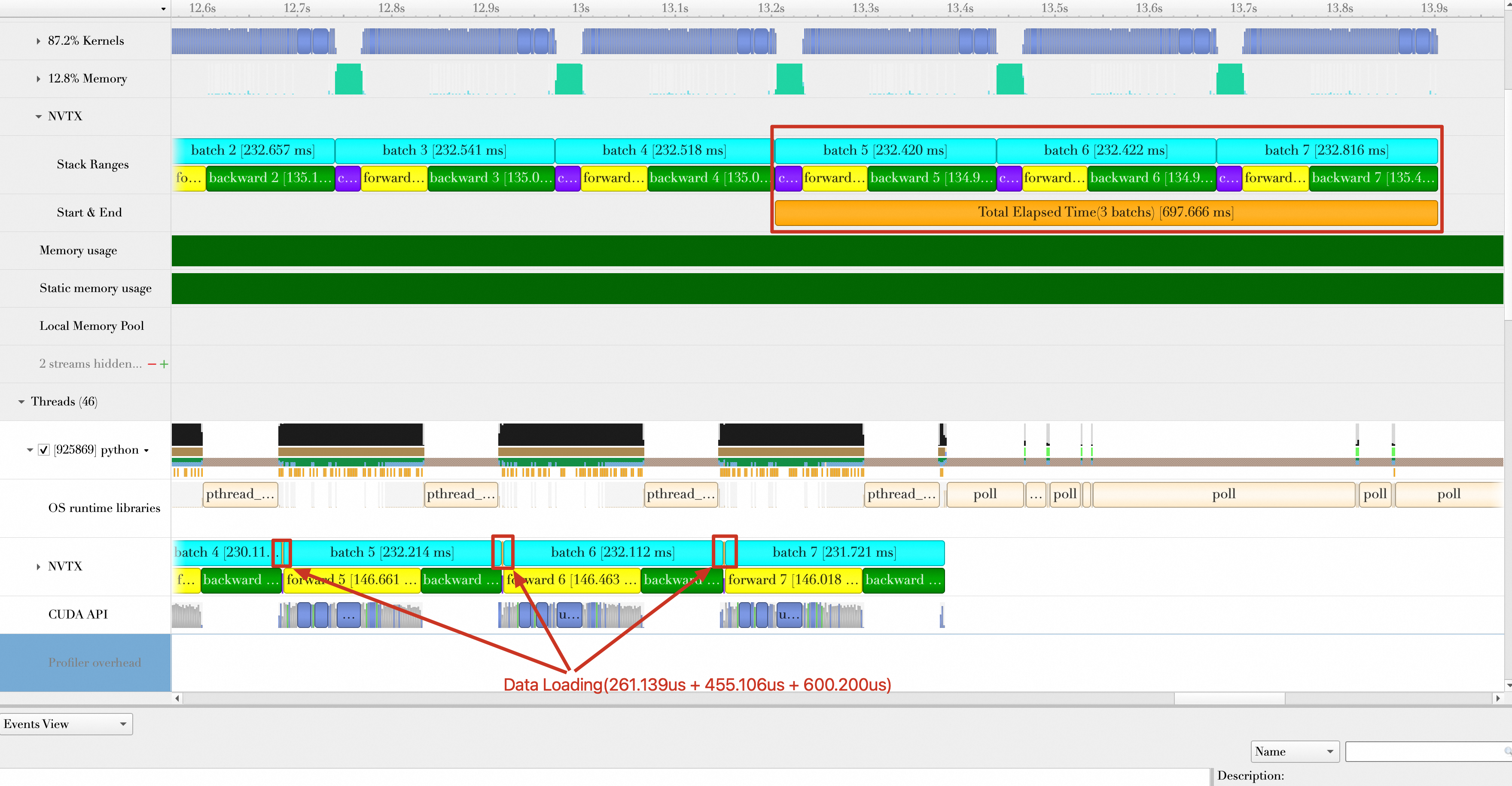
优化方向6:模型编译
默认情况下,PyTorch采用的是即时编译,您可以借助PyTorch的编译API将模型编译成图模式(Graph Mode)。
修改如下代码:
1 | model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device) |
运行代码,结果显示如下。总的持续时间为:567.971 ms,平均每秒处理的样本数为:512 * 3 /(567.971 / 1000)= 2704.36,性能提升(2704.36 - 2201.627)/ 2201.627 * 100% = 22.83%。
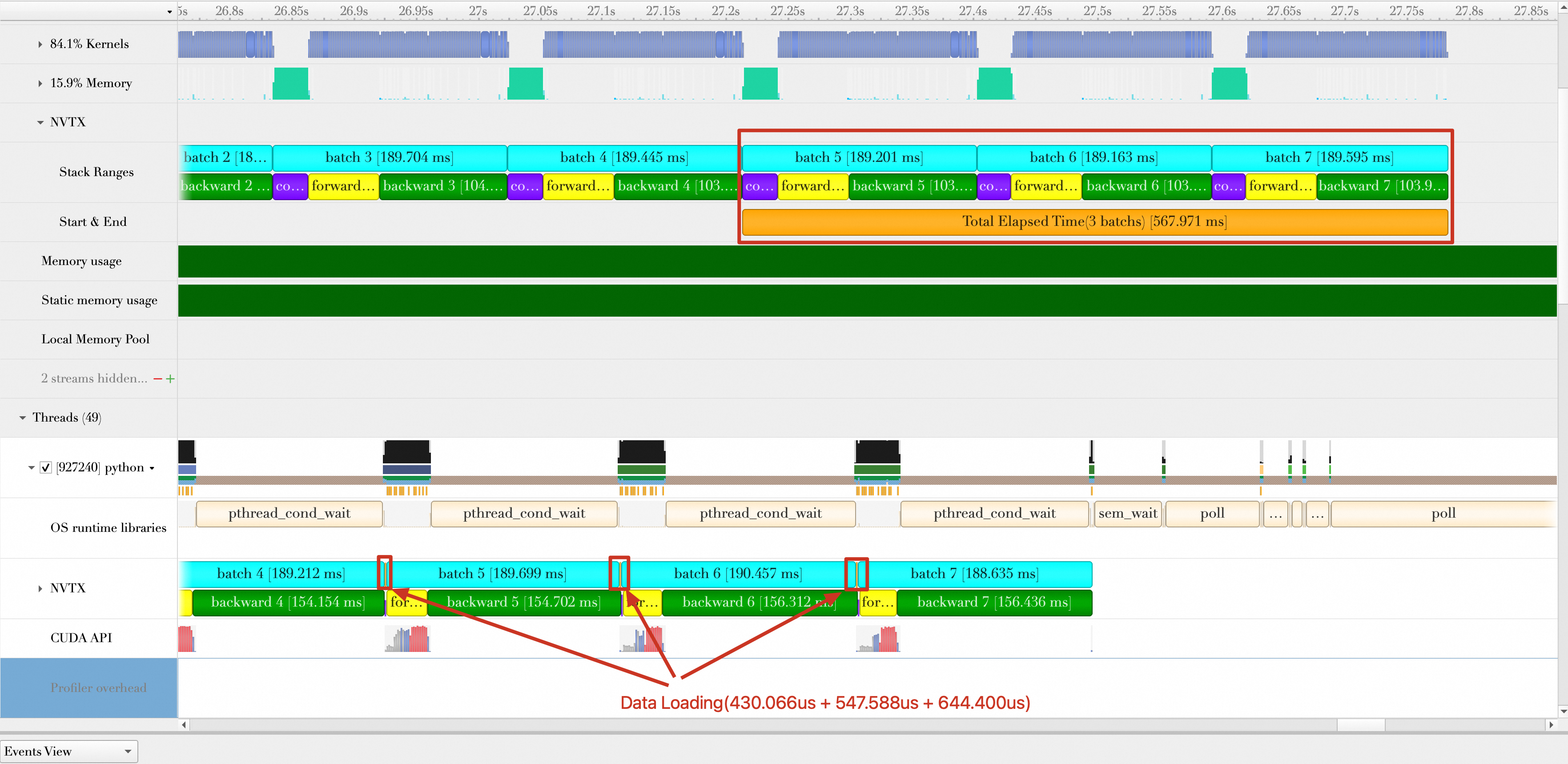
优化方向7:Batch传输与Batch计算重叠
由于Batch传输和Batch计算是串行执行的,也就是Batch传输完成,才能执行Batch计算。而Batch传输时,GPU是处于空闲状态的,然后当Batch Size变大时,Batch传输时间相比Batch计算是不可忽略的。
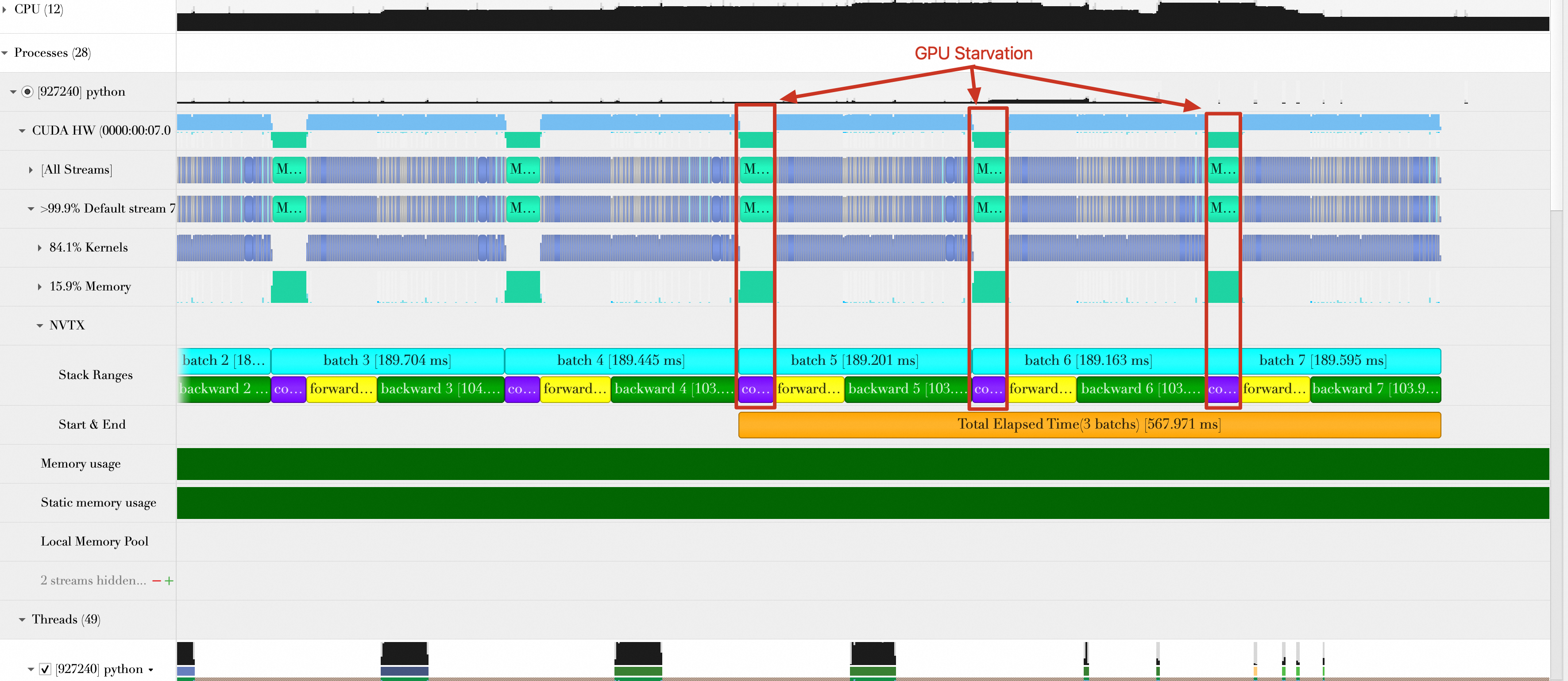
按照一般的思维,要计算Batch,只有当Batch传输到GPU后,才能开始计算,如果传输没有完成就开始计算,结果就不是正确的。如果以流水线思维思考,假设Batch计算的时间比Batch传输的时间长,那么如果GPU在计算第一个Batch的同时,第二个Batch也开始传输,等GPU计算第二个Batch的同时,第三个Batch传输也在进行,那么就将Batch传输的时间隐藏在Batch的计算中了。
在单个Stream中无法完成上述的重叠操作,不过PyTorch允许创建多个Stream,除了默认的Stream外,可以额外创建一个Stream。完整代码如下:
1 |
|
运行代码,结果展示如下。图中展示了Batch2到Batch7的传输操作隐藏在了Batch1到Batch4的计算中(Batch0和Batch1的传输未展示,页面有限)。同时可以确认的是,每个Batch在计算之前,其数据都已经传输完成。例如,Batch4计算时,Batch4的传输已经隐藏在Batch2的计算中。因此,可以确保计算结果的正确性。
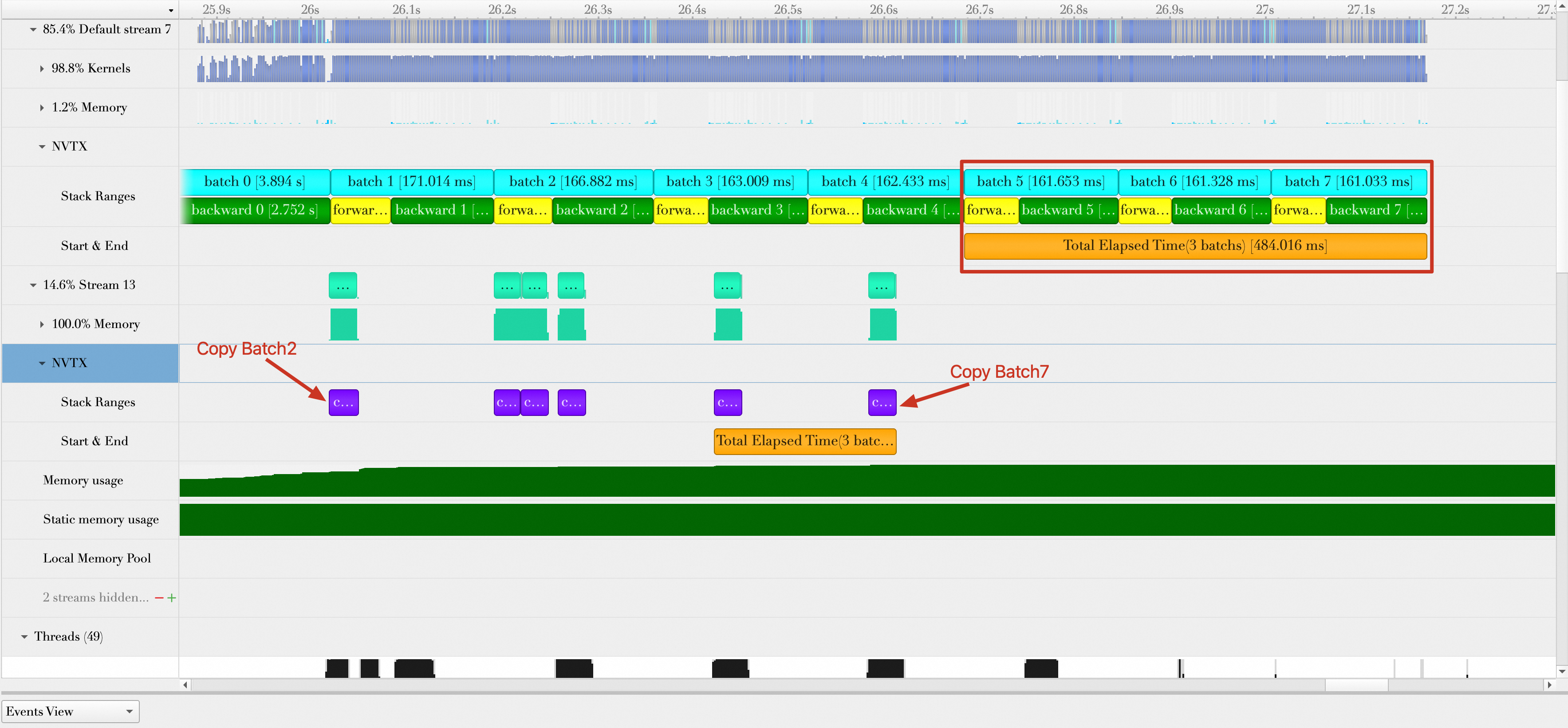
总的持续时间为484.016 ms,平均每秒处理样本数为:512 * 3 / (484.016 / 1000) = 3173.449,性能提升(3173.449 - 2704.36)/ 2704.36 * 100% = 17.35%。
需要注意的是,虽然将数据传输隐藏在数据计算中,但是会额外增加GPU内存的使用,以上面为例,当计算Batch5时,所有的Batch都驻留在了GPU内存中。
总结
对各个优化项性能提升做一个总结。
| 阶段 | 平均每秒处理样本数(samples/s) | 性能相比前一个优化项提升百分比 |
|---|---|---|
| 未优化:Baseline | 542.746 | - |
| 优化1:Data Loader worker设置为8 | 797.819 | 47.00% |
| 优化2:开启Pin Memory | 964.485 | 20.89% |
| 优化3:数据加载与Batch计算完全重叠 | 1019.498 | 5.7% |
| 优化4:自动混合精度 | 1628.83 | 59.77% |
| 优化5:增大Batch Size | 2201.627 | 35.17% |
| 优化6:模型编译 | 2704.36 | 22.83% |
| 优化7:Batch传输与Batch计算重叠 | 3173.449 | 17.35% |
模型训练推理优化实践(一):训练优化