
多线程内存模型(1):指令重排序
内存模型是多线程编程中非常复杂的概念,在了解这些内容之前需要了解一下前置知识
指令重排序
首先也是最复杂的部分:代码重排序。编译器和 CPU 能够重新排列程序指令,这些操作之间是相互独立的,编译器可以重新排列指令,然后 CPU 可以再次重新排列指令。
编译器重排序
编译器可能会改变源代码中指令的顺序,以提高代码的执行效率。例如优化寄存器的使用次数,优化内存布局和实现指令并行。
一般来说,只有没有关系的两条指令才有可能被重排,例如这段代码:
1 | int x = 1; |
这种情况先初始化x还是先初始化y对程序逻辑没有影响。重排序是为了代码有更好的效率,例如这段代码:
1 | //优化前 |
交替的读x、y,会导致寄存器频繁的交替存储x和y,最糟的情况下寄存器要存储3次x和3次y。如果能让x的一系列操作一块做完,y的一块做完,理想情况下寄存器只需要存储1次x和1次y。
CPU乱序执行
指令重排序是处理器层面做的优化。处理器在执行时往往会因为一些限制而等待,如访存的地址在cache中未命中,这时就需要到内存甚至外存去取,然而内存和外区的读取速度比CPU执行速度慢得多。
早期处理器是顺序执行(in-order execution)的,在内存、外存读取数据这段时间,处理器就一直处于等待状态。现在处理器一般都是乱序执行(out-of-order execution),处理器会在等待数据的时候去执行其他已准备好的操作,不会让处理器一直等待。
满足乱序执行的条件:
- 该缓存的操作数缓存好
- 有空闲的执行单元
对于下面这段汇编代码,操作1如果发生cache miss,则需要等待读取内存外存。看看有没有能优先执行的指令,操作2依赖于操作1,不能被优先执行,操作3不依赖1和2,所以能优先执行操作3。
所以实际执行顺序是3>1>2
1 | LDR R1, [R0];//操作1 |
缓存一致性重排序
这是指令重排序最难理解的部分,是由缓存不一致导致的重排序,我们先来看一段代码:
1 |
|
注:这段代码在现代编译器和现代操作系统的优化下已经不再会抛出异常了。
这段代码是有可能抛出x≠1的异常的,对于thread1来说,是先执行x=1再执行y=1,但是对于thread2来说,有可能是先执行y=1再执行x=1,即两个线程看这一段代码的执行顺序可能不一样。这种差异是由缓存不一致导致的,CPU的缓存架构如下。
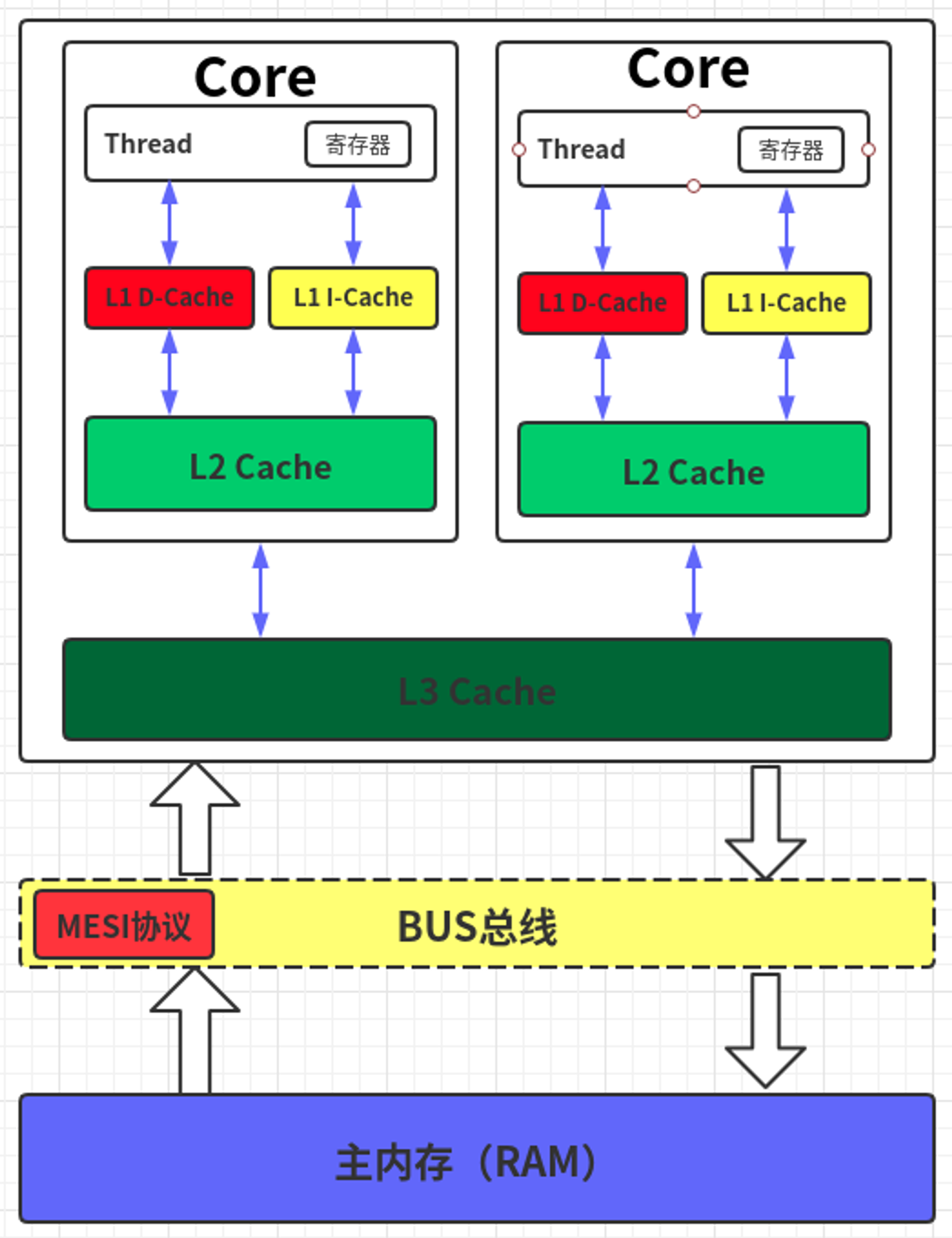
每个核都有自己专属的L1和L2缓存,而所有核共享L3缓存。变量赋值的移动顺序一般是:内存→L3缓存→L2缓存→L1缓存→寄存器。赋值操作后,变量值需要通过缓存一致性协议传播到L3缓存,再由L3缓存同步到其他核。在变量赋值后到更新到L3缓存之前,该变量的赋值对其他核是不可见的。
假设在thread1中,核先执行x=1,再执行y=1。但是,如果y的赋值先被刷新到L3缓存,而x的赋值后被刷新,那么对其他核来说,顺序会变成先看到y=1,再看到x=1。这是变量的更新顺序在多个缓存层之间传递时,引入的重排序。
多线程视角下的指令重排
as-if-serial规则
无论编译器和CPU对指令如何重排,都不会影响单线程下的运行结果,这也被称为as-if-serial规则。as-if-serial规则保证了程序在单线程执行的正确性,但在保证多线程执行的正确性上却无能为力。例如这段代码:
1 | // demo.cpp |
编译时开启O2优化
1 | g++ demo.cpp -o demo -lpthread -O2 |
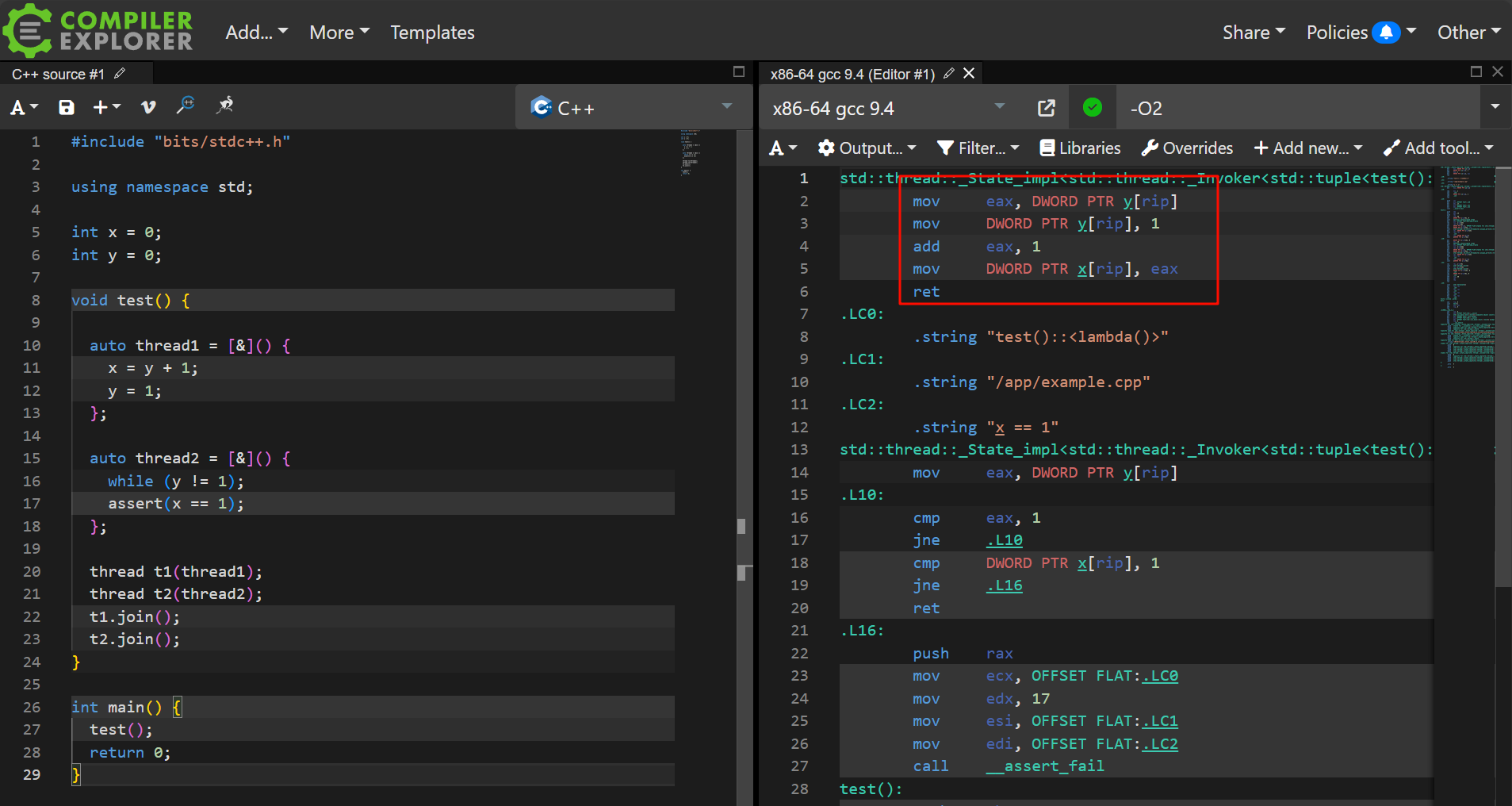
由于编译器的指令重排,导致y=1的赋值指令在x=y+1赋值指令之前,这段线程t1的运行没有影响,但是却影响了线程t2的执行结果。
happens-before规则
happens-before是并发编程中的一个概念,用于描述多线程运行时两个操作之间的顺序关系。如果一个操作A happens-before另一个操作B,则必须保证执行语义与A在B之前执行的语义一致。
多线程编程没有像单线程as-if-serial规则这样强有力的规则来保证执行的正确性,但C++也 提供了一系列的happens-before规则来保证在多线程环境运行下的顺序。
- 程序顺序规则(Program Order Rule):
- 单个线程内的每个操作都 happens-before 该线程中随后进行的任何操作,即as-if-serial规则。
- 锁定规则(Locking Rule):
- 解锁一个互斥锁 happens-before 该互斥锁的任何后续加锁。
- 条件变量规则(Condition Variable Rule):
- 通知(notify)某个条件变量 happens-before 任意一个随后对该条件变量的等待(wait)成功返回。
- 原子操作规则(Atomic Operation Rule):
- 一个原子操作上的释放(release)操作 happens-before 另一个线程中该原子操作上的获取(acquire)操作。
- 线程启动和结束规则(Thread Start and Join Rule):
- 一个线程的启动(std::thread 构造函数) happens-before 该线程中执行的任何操作。
- 一个线程的结束(std::thread 的 join 或 detach) happens-before join 返回或者 detach 完成。
内存一致性
操作使用使用内存一致性协议MESI来保证各个核内部缓存数据的一致性,但是完全的确保顺序一致性需要很大的代价,不仅限制编译器的优化,也限制了CPU的执行效率。为了更好地挖掘硬件的并行能力,现代的CPU多半都是介于两者之间,即所谓的宽松的内存一致性模型(Relaxed Memory Consistency Models)。
由于内存一致性不能保证,也导致了多线程编程时的资源竞争,如读脏数据、更新丢失和指令重排。
参考文档
https://www.cnblogs.com/zhongqifeng/p/14889070.html
https://mp.weixin.qq.com/s/Unh56s2FI5eMaeDjrGcGrw
https://www.0xffffff.org/2017/02/21/40-atomic-variable-mutex-and-memory-barrier/
多线程内存模型(1):指令重排序